μarchonomicon: Return Instructions
Table of Contents
Some notes and impressions about the properties of return instructions.
Setting up the Stack
Somewhere along the road, we decided that it's useful to represent programs as "a stack of different procedures." This has made a lot of people very happy and has been widely regarded as a good move. An ISA usually makes this easier for us by explicitly defining "call" and "return" instructions for entering and exiting procedures. But how are these implemented? And why?
Most of this is just an excuse to talk about branch predictor behavior [yet again] - but don't worry, it ends up being extremely simple, and there's only a little bit of context to deal with first.
Motivating Call and Return
Let's assume that we're dealing with some RISC-like pseudocode.
Imagine we have a program like this, where all of the jmp targets can
be known statically before runtime. All of these can be regarded as
direct changes to control-flow: each jmp has a single unambiguous
target address.
start:
jmp foo_1
_ret_1:
...
jmp foo_2
_ret_2:
...
halt
foo_1:
mov r0, #0xdead
jmp _ret_1
foo_2:
mov r0, #0xdead
jmp _ret_2
This program uses the same procedure twice. It's kind of like the expected
behavior of "call and return", but it has some duplicated code that we want
to get rid of. How are we supposed to do this exactly? We can't just define a
single instance of foo and expect to continue using jmp like before:
start:
jmp foo
...
jmp foo
...
halt
foo:
mov r0, #0xdead
jmp ??? // Uh oh, where are we supposed to return to?
Before, we had two copies of foo: one for each time (or "each distinct
point in the program") where it needed to be used. Now, we're left with
no way to distinguish when foo was called, and with no way to get back to
where we came from! Notice that all of the ambiguity here occurs when
we need to return from a procedure back to the caller.
From a purely "static" point of view, we simply don't have enough information
to correctly express this program, and our version of the jmp instruction
here isn't sufficient for doing this.
In order to return from foo, we'd need the machine to have some way of
remembering the path that we took into foo during runtime.
Indirection
As far as I can tell, an ISA really only needs two things to give us this behavior:
- A "call" instruction, which jumps to the address of some procedure and simultaneously stores the address of the next-sequential instruction somewhere (this is usually called the "return address")
- A "return" instruction, which loads a return address from somewhere and jumps to it
In this sense, a return instruction is really just an indirect change in control-flow with a special purpose: return to the instruction that comes after the most-recent previous procedure call.
Indirect branches are very special because they do not necessarily have a single fixed target address: instead, they let us write programs that dynamically load a target address from some part of the architectural ("programmer-visible") state.
Different instructions sets specify this behavior in slightly different ways. Here are a couple easy examples to look at while you stew on this.
Example: RISC-V
I think this is most obvious in the case of the RISC-V ISA:
-
"Call" behavior is captured by
JAL(relative jump and link) andJALR(indirect jump withrs1and link), which both save the return address to the register specified byrd -
"Return" behavior is a special case of
JALRwherers1is the register containing the return address, andrdis left unused (set to the zero registerx0).
Rearticulating our pseudocode from before into RISC-V:
start:
jal x1, foo // Put the return address in x1
...
jal x1, foo // Put the return address in x1
...
foo:
...
jalr x0, x1 // Return to the address in x1
This is enough to give us the "call and return" behavior that we expect. In RISC-V, the return instruction is very obviously indistinguishable from an indirect branch.
It's also worth mentioning that the RISC-V specification suggests that
the programmer can use x1 as a "link register" for this purpose,
but the JAL and JALR instructions do not do this for us automatically.
In this case, the idea of a dedicated link register is a convention that
isn't actually embodied in the behavior of any instruction defined by the ISA.
Example: ARM
On the other hand, the ARM ISA goes one step further and actually enshrines the idea of a link register by providing instructions which explicitly use it:
- The
BLandBLRinstructions automatically save the return address to the link register - The
RETinstruction is an indirect jump where:- The encoding is distinct from
BLRand does not save a return address - The source register operand defaults to the link register
- The encoding is distinct from
This lifts some of the burden in the case of "leaf functions." Since these instructions always use the link register, the programmer isn't always forced to worry about where the return address will be.
start:
bl foo // Put the return address in the link register
...
bl foo // Put the return address in the link register
...
foo:
...
ret // Return to the address in the link register
However, in ARM and RISC-V, the idioms for call and return don't necessarily help programmers in cases where procedure calls are expected to be nested. In those cases, we still need to keep track of the "call stack" of previous return addresses. This typically involves copying the previous return address somewhere else: usually to some location in a remote memory.
Example: x86
The x86 approach is slightly different in that the return address is not
kept in a general-purpose register at all. Instead, return addresses are
are stored in main memory by using the address of the stack pointer rsp.
CALLstores the return address at the location given by the stack pointer, and then increments the stack pointerRETloads the return address from the location given by the stack pointer, and then decrements the stack pointer
Instead of expecting the programmer to provide a GPR, the x86 ISA assumes that the return address will always be recovered by loading the value from the top of the call stack [in some remote memory].
start:
call foo // Put the return address in [rsp]
...
call foo // Put the return address in [rsp]
...
foo:
...
ret // Return to the address in [rsp]
This makes it somewhat simpler to deal with leaf functions and nested calls, so long as the programmer is able to faithfully maintain the stack and the value of the stack pointer.
Predicting a Return Instruction
Unsuprisingly, the typical scheme for predicting return instructions is implemented with stack-like structure for storing predicted return addresses: this is usually called the "Return Stack Buffer" (RSB) or "Return Address Stack" (RAS).
A RAS is maintained [transparently by hardware] in the same way that we manage an architectural stack, although the capacity of the RAS is comparatively very small:
- When a call is encountered, push the return address on top of the RAS
- When a return is encountered, pop the most-recent entry to make a prediction
This takes advantage of the assumption that a meaningful return address always links a return instruction to a previous call instruction. In this sense, the presence of a return instruction always constitutes a kind of "hint" to the machine.
Now assuming that the programmer has succeeded at keeping track of return addresses, predictions from the RAS should always correspond to the correct architectural return address.
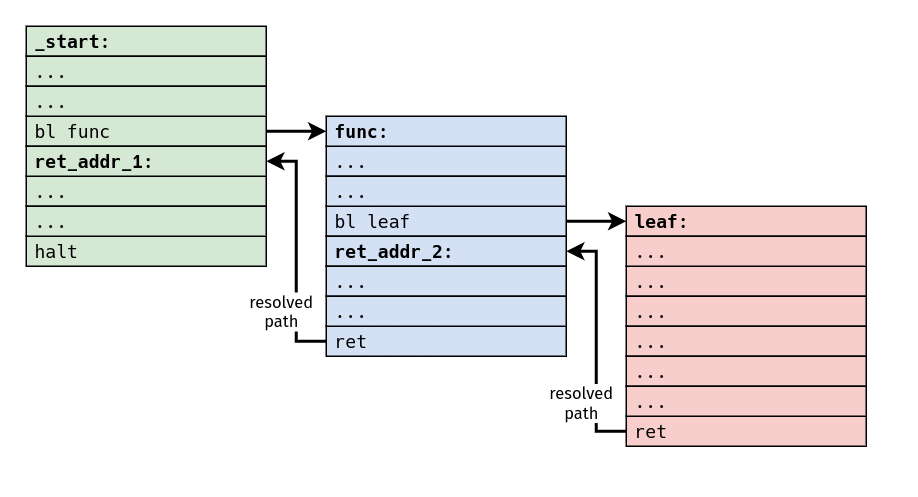
This eliminates the latency associated with needing to resolve the return
address, and it means that the machine can begin dealing with the instructions
at ret_addr_2 [and beyond!] ahead of time.
As a result of this, any reasonable machine should always predict that the target of a return is the next-sequential address following the most-recent, previous call instruction.
The cost of not making this assumption is pretty high, and basically amounts to stalling the pipeline for the completion of each and every return instruction. Branch prediction schemes for other kinds of branches can become pretty complicated, but the case for return instructions is comparatively very simple and very effective.
Mispredicting a Return Instruction: Capacity
Since the capacity of a RAS implementation is very limited, it's very easy to imagine situations where the RAS will necessarily fail at keeping track of a return address: this always happens in cases where the depth of nested procedure calls exceeds the capacity of the RAS.
Imagine we have a toy machine with only three RAS entries, and we'd like to run a program with four consecutive calls followed by four consecutive returns:
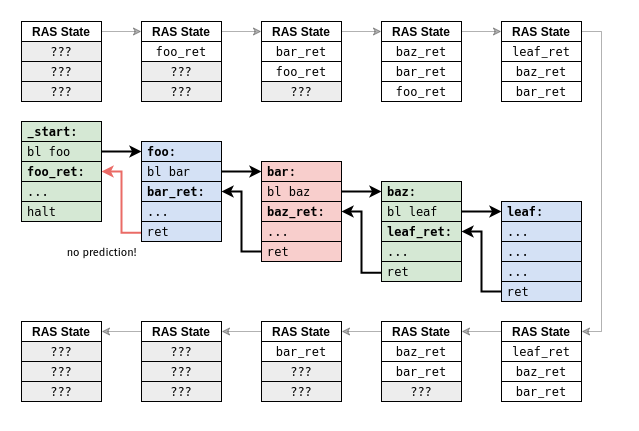
When we reach the fourth call, the return address foo_ret ends up being
discarded from the RAS in order to make room for leaf_ref.
By the time we reach the fourth return, we find the that RAS is empty and
cannot be used to make a meaningful prediction. The fourth call amounts to an
overflow condition in the RAS, and the fourth return is forced to deal with
the consequences of an underflow condition.
This picture assumes that storage for a RAS is distinct from the storage associated with a branch target buffer (BTB), which is usually much larger and used to cache target addresses for many different kinds of branches.
In addition to relying on a RAS, you might also decide to treat return instructions like any other indirect branch and store their target addresses in a BTB after they've been resolved. This is one way of handling situations where the RAS is empty and cannot provide a prediction.
This happens to be part of the mechanism behind Retbleed: for sufficiently deep call stacks in privileged code, return instructions may also subject to "branch target injection." If the BTB entry associated with a return instruction can be influenced by unprivileged code, this amounts to control over speculation into privileged code (which an attacker might try to use as a gadget for leaking information).
Mispredicting a Return Instruction: Breaking a Promise
There's another idea which is kind of obvious, but I think it's still interesting: this predictor has a "blind spot," and it's trivially easy for a program to defeat this branch prediction scheme. If a program can change the value of the return address in between call and return, that return instruction must always end up being mispredicted.
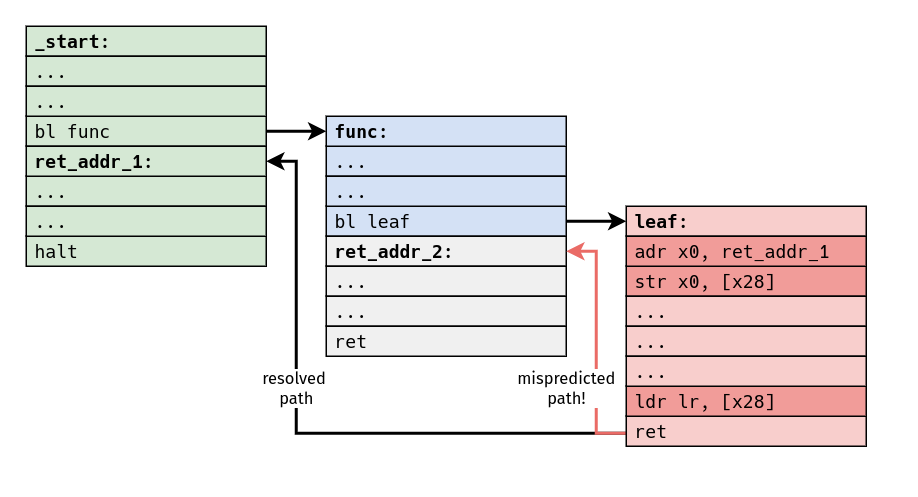
This is ultimately a consequence of the fact that, at least in all of the machines we've considered here, return addresses always end up being part of the architectural state in some way or another. For whatever reason, it always ends up being the programmer's responsibility to deal with storage for return addresses, and some machines can only partially abstract this away from us, if at all.
I get the impression that this is a projection of some "deep truth" about how we've collectively decided to design general-purpose computers, but I'm not sure that I have a single coherent package for it.
Please consider these hand-wavy, half-baked thoughts instead (in no particular order):
-
The utility behind an indirect branch is that it represents a place in the program where we'd like to relax the distinction between control and data.
-
We ideally want machines to handle arbitrarily deep stacks of procedures, but when we end up implementing this, all of the memories large enough for this task are necessarily very far away from the core.
-
Instruction sets in general-purpose machines specify call and return instructions in a pretty relaxed way; the use of call and return really only constitutes a promise to the machine that a program is free to (intentionally or unintentionally) break at any time.
-
Can we imagine a machine where the use of call and return is more like a contract, and less like a promise? Is this something we might want?