Some Notes on Zenbleed
Table of Contents
This article explores the conditions for triggering "Zenbleed" (CVE-2023-20593).
Back in July, the embargo on "Zenbleed" was lifted. This is a CPU bug that affects the floating-point/vector pipeline in Zen 2 cores. In short, this creates a situation where unrelated values from the floating-point physical register file may leak into the upper-half of a 256-bit YMM register.
Tavis Ormandy has already published a stellar writeup about how this bug works, complete with great visual analogies to memory safety bugs that we normally see in software. The proof-of-concept1 is also terrifyingly good at communicating the impact of the bug.
Despite being totally satisfied by that writeup, there are lingering questions I had about some of the conditions for triggering the bug. This is mostly what we're going to be exploring here.
I'm not really going to be speculating about the underlying root cause of the bug this time - instead, I thought it might be more useful to talk about pieces of the puzzle that are plainly visible to us in software (ie. with PMCs).
I wrote this while assuming that you've already read through Tavis' analysis, and that you're already familiar reasoning about these kinds of things. I'll try my best to give you context where I think it's necessary. Feel free to reach out if you have any feedback.
Setting up the Stack
The goal here is to devise some kind of kind of minimal test that reproduces the bug on a single hardware thread. The POCs are all focused on demonstrating how values may leak from another hardware thread on the same physical core, but we aren't really interested in this aspect of it. Instead, we're doing all of this with SMT disabled.
I chose to start with the variant that mispredicts an indirect jump, but we might end up looking at other cases too. I'm not going to talk about this in detail (in the interest of time), but before each test, there are two things that I'm doing beforehand:
- Flushing the BTB and hoping that we consistently mispredict our jump
- Filling the PRF with nonzero values so we can see when something leaks
Here's the first version of our test, which isn't substantially different from the original POC:
// Flush the BTB.
...
// Fill the physical register file with nonzero values.
...
// Put LFENCE at the end of a 64-byte block.
// The gadget will be aligned to a 64-byte boundary.
.align 64
_start:
nop8
nop8
nop8
nop8
nop8
nop8
nop6
lea r8, [_branch_target]
lfence
// These are the four instructions we need to worry about.
_gadget:
vpinsrb xmm0, xmm0, r13d, 0
vmovdqu ymm0, ymm0
jmp r8
vzeroupper
// The branch target is a 64-byte aligned LFENCE.
.align 64
_branch_target:
lfence
vmovupd [rdi], ymm0
...
The only real difference here is that we've explicitly aligned each of the
three parts, explicitly separated them with LFENCE, and then removed some
instructions that that aren't necessary for triggering the bug.
Zen 2 machines are typically configured with DE_CFG[1] set, indicating that
LFENCE is dispatch-serializing. Dispatch is stalled until LFENCE retires,
and any instructions that come before LFENCE are guaranteed to retire before
the LFENCE itself.
In this case, we're using it to clarify that the state before and after the gadget is architectural. This also has the effect of guaranteeing that all of the instructions in the gadget will be dispatched together, but we'll talk more about that later.
I found that this acts mostly-predictable on my machine, but it's still flaky
on occasion. Despite the fact that the bug isn't necessarily triggered every
single time I run the test, there's an upside: every time I run a set of tests,
I can always tell whether or not the bug was triggered. On top of that, the
PMCs show that the bug always coincides with speculative dispatch of
VZEROUPPER.2
I should also mention that, since we're polluting all of the XMM/YMM registers before running this code, we expect that the Z-bit is unset on all register map entries. The upper half portion of all YMM registers is guaranteed to be nonzero.
Architectural State
The remarkable thing about this bug is that it corrupts the architectural
state of the machine.
In any case, we expect that VPINSRB must result in the following
architectural effects on the destination YMM register:
- The lower half of YMM0 is changed
- The upper half of YMM0 is set to zero
Despite this, by the time we reach the end of the gadget, we find that the value in the upper half is not zero! During the gadget, we have somehow managed to rollback or cancel-out an effect on the machine that should have been unambiguously architectural.
// At this point, the upper half of YMM0 is nonzero
lfence
// VPINSRB must set the upper half of YMM0 to zero
vpinsrb xmm0, xmm0, r13d, 0
vmovdqu ymm0, ymm0
jmp r8
vzeroupper
// The upper half of YMM0 is nonzero again?
.align 64
lfence
vmovupd [rdi], ymm0
I quickly became confused while staring at this because all of the register operands here are referring to YMM0. Since we expect to be reasoning about effects on the register map, we should try to disambiguate all of the references to register operands here.
lfence
vpinsrb xmm1, xmm0, r13d, 0
vmovdqu ymm2, ymm1
jmp r8
vzeroupper
.align 64
lfence
vmovupd [rdi], ymm2
Now that we can actually distinguish between the effects of the first two
instructions on the register map, we can just change the source of VMOVUPD
and check their values at the end of the test. After the gadget, we find the
following:
- The upper half of YMM0 is nonzero
- The upper half of YMM1 is zero
- The upper half of YMM2 is nonzero
This suggests that the register map entry for the result of VPINSRB
appears to be in the expected state, but the entry for the result of
VMOVDQU is incorrect.
When moving one register to another, we normally expect that the underlying
value does not change at all.
Ordering and Dispatch
All of this made me think about the ordering of events in the pipeline, especially because we expect that all of these instructions are dispatched at the same time. Ultimately, it seems like something strange is going on in the rename/dispatch part of the pipeline.
The first order of business is to invoke our copy of the Family 17h SOG3 and scan for clues about the behavior during dispatch. The total size of the dispatch window is constrained by how many ops can be inserted into the retire queue:
The retire control unit (RCU) tracks the completion status of all outstanding operations (integer, load/store, and floating-point) and is the final arbiter for exception processing and recovery. The unit can receive up to 6 macro ops dispatched per cycle and track up to 224 macro ops in-flight.
Although the SOG says that the dispatch window can be six micro-ops, I get the impression this is only possible under certain conditions. I didn't want to dig into it too hard (since it seemed like an unnecessary tangent), but after doing some brief tests, I only observed dispatch windows up to five micro-ops. The rest of the article will simply assume that the dispatch window is effectively only five micro-ops.
Since the machine is split into integer and floating-point parts, there are additional constraints on how many different kinds of ops are allowed for dispatch in a single cycle. Looking at the section for the floating-point pipeline:
The floating-point unit (FPU) utilizes a coprocessor model for all operations that use X87, MMX™, XMM, YMM, or floating point control/status registers. As such, it contains its own scheduler, register file, and renamer; it does not share them with the integer units. It can handle dispatch and renaming of 4 floating point micro ops per cycle and the scheduler can issue 1 micro op per cycle for each pipe. The floating-point scheduler has a 36 entry micro-op capacity. The floating-point unit shares the retire queue with the integer unit.
With that in mind, after measuring the number of micro-ops in our gadget, we
find that there are exactly five micro-ops: four floating-point ops, and one
integer op for the JMP. Apparently, VPINSRB actually consists of two
micro-ops.
This all fits conveniently into a single dispatch window:
vpinsrb xmm1, xmm0, r13d, 0 // Slot 0/1 (FP)
vmovdqu ymm2, ymm1 // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
.align 64
_branch_target:
I thought it might be more useful to swap VPINSRB for another instruction
that also clears the upper half of the destination YMM register, but only
decodes into only a single micro-op. It's a little bit easier to reason about
when our assembly actually corresponds one-to-one with the micro-ops flowing
through the pipeline.
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
vmovdqu ymm3, ymm2 // Slot 1 (FP)
jmp r8 // Slot 2 (INT)
vzeroupper // Slot 3 (FP)
.align 64 // The first NOP here should occupy slot 4
_branch_target:
There are a lot of alternatives, and I chose VPADDQ for no reason in
particular. This clears the upper half of YMM2, and is only a single micro-op.
However, this version of the gadget doesn't appear to trigger the bug, and we
always find that the upper half of YMM3 is zero as expected.
At this point, it seems like the order of ops within the dispatch window really does make a difference here, so we should probably try rearranging them.
I first tested with a padding NOP in different places:
// This doesn't work! - the upper half of YMM3 is zero
nop // Slot 0 (INT)
vpaddq xmm2, xmm0, xmm1 // Slot 1 (FP)
vmovdqu ymm3, ymm2 // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
// This doesn't work! - the upper half of YMM3 is zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
nop // Slot 1 (INT)
vmovdqu ymm3, ymm2 // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
// This doesn't work! - the upper half of YMM3 is zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
vmovdqu ymm3, ymm2 // Slot 1 (FP)
nop // Slot 2 (INT)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
// This doesn't work! - the upper half of YMM3 is zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
vmovdqu ymm3, ymm2 // Slot 1 (FP)
jmp r8 // Slot 2 (INT)
nop // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
But it looks like the bug isn't triggered in any of these cases!
On second thought, our original test with VPINSRB had four floating-point
ops, but this version only has three.
We can just repeat this, but with FNOP instead of NOP:
// This works! - the upper half of YMM3 is not zero
fnop // Slot 0 (FP)
vpaddq xmm2, xmm0, xmm1 // Slot 1 (FP)
vmovdqu ymm3, ymm2 // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
// This works! - the upper half of YMM3 is not zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
fnop // Slot 1 (FP)
vmovdqu ymm3, ymm2 // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
// This doesn't work! - the upper half of YMM3 is zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
vmovdqu ymm3, ymm2 // Slot 1 (FP)
fnop // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
// This doesn't work! - the upper half of YMM3 is zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
vmovdqu ymm3, ymm2 // Slot 1 (FP)
jmp r8 // Slot 2 (INT)
fnop // Slot 3 (FP)
vzeroupper // Slot 4 (FP)
// This doesn't work! - the upper half of YMM3 is zero
vpaddq xmm2, xmm0, xmm1 // Slot 0 (FP)
vmovdqu ymm3, ymm2 // Slot 1 (FP)
jmp r8 // Slot 2 (INT)
vzeroupper // Slot 3 (FP)
fnop // Slot 4 (FP)
This seems to be telling us that the bug can only occur when four floating-point ops are dispatched at the same time. It also looks like we need them to be in some particular order within the dispatch window, but the conditions aren't clear yet.
We can also ask another related question: is is really necessary for
VPADDQ (or any other instruction we decide to use for setting the Z-bit)
to live in the same dispatch window as VMOVDQU and VZEROUPPER?
// Let VPADDQ retire *before* the gadget is dispatched
vpaddq xmm2, xmm0, xmm1
lfence
// This works! - the upper half of YMM3 is not zero
fnop // Slot 0 (FP)
fnop // Slot 1 (FP)
vmovdqu ymm3, ymm2 // Slot 2 (FP)
jmp r8 // Slot 3 (INT)
vzeroupper // Slot 4 (FP)
.align 64
_branch_target:
lfence
vmovupd [rdi], ymm3
Apparently not! - this also lets us see the bug. It seems like it's
sufficient that the Z-bit for YMM2 has been set at any time in the past,
and this doesn't need to occur at dispatch along with VMOVDQU and
VZEROUPPER.
I tried shifting these around again, but this is the only case that works!
For whatever reason, it seems like the bug depends on VMOVDQU and
VZEROUPPER being at these points in the dispatch window.
The DE_CFG Chicken Bit
On my machine (Matisse), microcode updates haven't been published yet.
In the meantime, the Linux kernel mitigates this issue by setting the
magic DE_CFG[9] bit when cores first come online. I had to turn this off
before testing any of this.
As far as I'm aware, nobody has really said anything about what this bit is
actually supposed to do!
Luckily, it ended up being fairly straightforward to test: I just spent a bit
of time using PMCs to measure this with the mitigation on and off.
After fumbling around "a bit" (violently diffing a lot of tests with
basically all of the PMC events), I eventually came to the conclusion that
DE_CFG[9] disables move elimination in the floating-point pipeline.
In short, you can observe this by looking at event PMCx004.
When the bit is set, we find that the mask 0x02 ("SseMovOpsElim") fails to
record any eliminated moves.
For whatever reason, this event is only documented in certain [mostly older]
versions of the PPRs for Family 17h4:
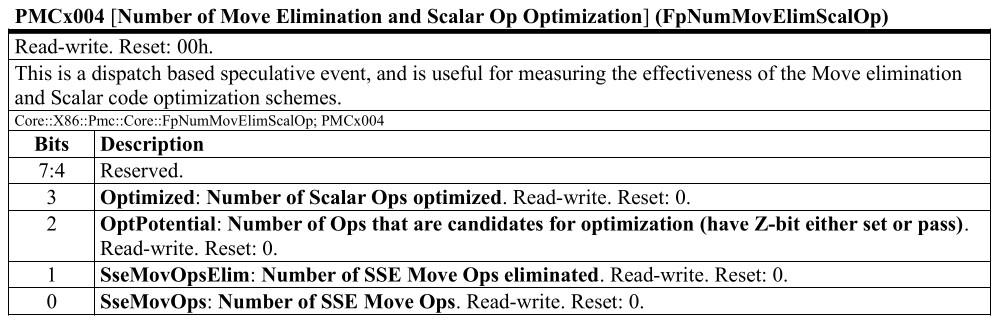 Figure 1. Description of
Figure 1. Description of PMCx004 (from document #54945)
Apart from eliminated moves, this also records cases where instructions are subject to the XMM register merge optimization. The documentation here also explicitly reminds us that both of these things occur speculatively at dispatch. This makes sense because both are optimizations that rely on the register map, and I guess it isn't too suprising that they're both involved in the bug.
SLS over a Direct Branch
As an aside, I thought it might be interesting to try testing this gadget with SLS over a direct jump instead of mispredicting an indirect jump, and I was sort of surprised that I couldn't get the bug to work.
Despite that, I noticed that the PMCs still record that VZEROUPPER is always
being speculatively dispatched. Shouldn't we still be triggering the bug?
...
vpaddq xmm2, xmm0, xmm1
lfence
// Let's try a direct JMP instead
fnop
fnop
vmovdqu ymm3, ymm2
jmp _branch_target
vzeroupper
// This doesn't work! - the upper half of YMM3 is zero
.align 64
_branch_target:
lfence
vmovupd [rdi], ymm3
I originally thought this should boil down to the difference between latency in both cases:
-
Indirect branches must be scheduled at dispatch. Resolving the target of an indirect branch always involves reading from the integer PRF, and that only happens after being issued in the out-of-order part of the machine. In this case, recovery from incorrect speculation can only begin after dispatch, and after the branch is completed in the backend.
-
Direct branches don't necessarily need to be scheduled, since the target can be resolved by adding the program counter to an immediate offset available at decode time. This means that incorrect speculation can be recognized before or during dispatch.
We can actually estimate the latency associated with these cases by
placing more padding and an extra FNOP somewhere after VZEROUPPER,
and then using the PMCs to check if an extra floating-point op has been
speculatively dispatched.
For the indirect branch, we find that the incorrect prediction lives long enough for an additional seven groups of five micro-ops to be speculatively dispatched.
Since the machine dispatches five micro-ops per cycle, I assume this means
that there are at least an additional seven cycles of latency before
we stop speculating sequentially past the JMP.
...
// Dispatch group 0
fnop
fnop
vmovdqu ymm3, ymm2
jmp r8
vzeroupper
nop; nop; nop; nop; nop // Dispatch group 1
nop; nop; nop; nop; nop // Dispatch group 2
nop; nop; nop; nop; nop // Dispatch group 3
nop; nop; nop; nop; nop // Dispatch group 4
nop; nop; nop; nop; nop // Dispatch group 5
nop; nop; nop; nop; nop // Dispatch group 6
nop; nop; nop; nop; fnop // Dispatch group 7
.align 64
_branch_target:
When we look at a direct branch instead, the speculative window is shorter
like we expect. In this case, only nine padding ops are dispatched after
the VZEROUPPER:
...
// Dispatch group 0
fnop
fnop
vmovdqu ymm3, ymm2
jmp _branch_target
vzeroupper
nop ; nop ; nop ; nop ; nop // Dispatch group 1
nop ; nop ; nop ; fnop // Dispatch group 2?
.align 64
_branch_target:
It seemed weird that this wasn't a multiple of the dispatch window size,
but then I realized that this isn't the right way of looking at it.
Instead, we should expect that by the time our gadget is being dispatched,
the machine has recognized that VZEROUPPER should not part of the first
dispatch group (along with VMOVDQU and the others).
In the meantime, the whole pipeline hasn't finished reacting to this fact,
and VZEROUPPER ends up being dispatched in the next group anyway,
only to be flushed shortly afterwards. This is the basic idea behind
cases of "straight-line speculation": while we're waiting for instructions
from the actual branch target, the machine doesn't have anywhere to go but
forward.
...
// Dispatch group 0 (cut short by the direct branch)
fnop
fnop
vmovdqu ymm3, ymm2
jmp _branch_target
// Dispatch group 1
vzeroupper
nop
nop
nop
nop
// Dispatch group 2
nop
nop
nop
nop
fnop
.align 64
_branch_target:
In this case, the size of the speculative window only indirectly explains
why the bug fails to occur here. More specifically, it seems like this
particular path [with SLS over a direct branch] is insulated because it
prevents VZEROUPPER from being dispatched in the same group as our gadget.
This fits in nicely with our previous observations about what needs to happen
at dispatch.
Breakpoint
So far, we've managed to narrow down some of the conditions needed to trigger the bug. Resummarizing some observations from before:
- The Z-bit has been set on the register map entry for some YMM register at any point before our gadget is dispatched
- Our gadget must occupy a single dispatch window:
- The first and second slots can be
FNOP - The third slot must be an eliminated move from target YMM register
- The fourth slot is some mispredicted branch
- The fifth slot is an incorrectly-speculated
VZEROUPPER
- The first and second slots can be
- Disabling move elimination prevents the bug from occuring
That's nice, although we really haven't come to any conclusion about why this should result in the architectural state being incorrect. On top of that, we didn't get around to thinking about the fact that after the bug occurs, the top half of YMM3 doesn't even have the value from the physical register that we moved from!
At this point, I think we can only repeat what Tavis has already said about
this: that it has something to do with the interaction between the move and
the flushed VZEROUPPER.
It's certainly possible that this is some kind of logic bug that we
might arrive at through some very careful analysis, but then again, it's also
possible that this is some kind of timing issue that concerns parts of the
machine that we have no real visibility into.
Bonus Context from Physical Design?
This is sort of tangential, but there's some more context about this whole situation that I thought was worth sharing.
Ultimately, "XMM register merge optimization" (or more generally, the idea of tracking zeroed registers) is motivated by physical design concerns.
If you spend any time looking at die shots from Zen 2 cores, one thing you'll notice is that the physical layout of the floating-point/vector part of the machine is very obviously split into two parts. The same thing is also true for Zen 3, and even for Zen 4 cores with AVX512 support5.
 Figure 2. Floating-point/vector blocks from various Zen cores.
Figure 2. Floating-point/vector blocks from various Zen cores.
These are crops of die photographs from Fritzchens Fritz on Flickr.
Presumably, these two parts of the machine correspond to the upper and lower parts of the floating-point/vector pipeline! This paints a nice picture where the distinction between the upper and lower halves of vector registers cut all the way through to the physical part of the design.
Apart from the fact that x86 splits the floating-point/vector registers for compatibility with different ISA extensions, tracking zeroed registers in the floating-point pipeline seems especially important since it directly translates to finer grained control over a large [and necessarily power-hungry] part of the machine.
Resources and Footnotes
On my machine (Matisse), speculatively dispatched micro-ops are counted by
PMCx0AB and the event mask 0x04 selects only the floating-point uops.
This event is undocumented in the Family 17h PPRs.
AMD talked about this briefly at Hot Chips 2023 last month: on Zen 4, the AVX512 implementation is split into two 256-bit datapaths.