Speculating on Zen 2 (Part 2)
Table of Contents
This is the second part of my exploration into branch prediction and speculation in the Zen 2 microarchitecture, where we look at the behavior of unconditional direct branches and continue digging into details about the branch predictor.
In the previous article, we looked briefly at the behavior of conditional branches, and then we reviewed some of AMD's documentation about the Zen 2 branch predictor. This article builds on some of the experiments in that one, and I'd strongly recommend reading it before starting this one - I'll be referring back to it frequently.
You can also find the code from this article on my GitHub, see eigenform/lamina-zen2-spec.
Context from Last Time
Last time, we decided to focus on finding a way to consistently cause
speculation. We planned on using performance-monitoring counters (PMCs)
to look at some speculatively-counted event (in our case, dispatched PREFETCH
instructions), in order to determine when our tests result in speculation down
a mispredicted path.
While looking at the AMD Software Optimization Guide1 (SOG), we found some information that fit our observations for "always-taken" and "never-taken" conditional [direct] branches:
-
Branches are always implicitly predicted as "not-taken," meaning the machine always speculates sequentially down the instruction stream by default
-
Predictions (to non-sequential target addresses) are only made after a branch has been installed in the branch target buffer (BTB), which only happens after a branch has been resolved "taken"
This meant that "never-taken" branches are never predicted taken, and conversely, "always-taken" branches are only mispredicted when a BTB entry is not present (when the branch is first discovered).
We also observed that it should be possible to consistently mispredict a "always-taken" conditional branch, but only if we do some extra work by clearing the newly-created BTB entry every time the branch is resolved. We decided to avoid this route and continue searching for other solutions.
A Note about Alignment
Instruction fetch occurs on 32-byte aligned addresses, and like we talked about last time, BTB entries are indexed by these addresses. I forgot to do this before, but in the interest of making things easier to think about, we should also try to pad the start of our test code to a cache line boundary.
This is also an excuse to show you the outer part of our test code, in case you haven't seen the previous article. Revising our code-generation macro from last time, we have:
macro_rules! emit_branch_test {
($ptr:ident $($body:tt)*) => { {
emit_rdpmc_test_all!(
// Context to make writing tests easier
; mov rdi, QWORD $ptr as _
; lea rsi, [->branch_target]
; lea rbx, [->end]
; xor rax, rax
// Manually emit some longer NOP encodings, in order to pad
// this LFENCE to the last 3 bytes in the cache line.
; .bytes NOP_15
; .bytes NOP_15
; .bytes NOP_15
; .bytes NOP_4
// Stop any speculative paths from entering our test code
; lfence
// The body of our test is inserted here at compile-time.
// This starts at a cache line boundary.
; ->test_body:
$($body)*
// Stop any speculative paths from escaping our test code
; lfence
)
} }
}
With that out of the way, let's look at unconditional direct branches.
Unconditional Direct Branches
The opposite of a conditional branch is an unconditional branch, where
the branch is always taken when encountered in the instruction stream.
In x86, this is the JMP instruction.
Here's our test code and a graph of the measured events over time:
let events = PerfCtlDescriptor::new()
// Dispatched PREFETCH instructions (speculative)
.set(0, Event::LsPrefInstrDisp(0x01))
// Retired branch instructions (mispredicted)
.set(1, Event::ExRetBrnMisp(0x00))
// Retired branch instructions
.set(2, Event::ExRetBrn(0x00));
let code = emit_branch_test!(scratch_ptr
// Unconditional direct branch to 'branch_target'
; jmp ->branch_target
// Unreachable target code
; prefetch [rdi]
; lfence
; .align 64
; ->branch_target:
; ->end:
);
run_test(&mut ctx, &events, &code, "jmp (direct)", "/tmp/jmp_direct.txt")?;

Notice how this has a similar pattern to the results from last article,
with the "always-taken" conditional branch. We see that PREFETCH is
speculatively-dispatched for the first run, and then the behavior is
corrected for the remaining tests. That probably indicates that the BTB
is involved in the exact same way as before.
There's an important difference here though: it seems like we didn't measure any branch mispredictions. Why would the PMCs fail to count a mispredicted branch here, even though we are definitely speculating down an incorrect path? How can there be incorrect speculation without an incorrect prediction?
More confusingly, if unconditional direct branches are always taken, then why do predictions seem to be involved here in the first place? Assuming that our test environment is sane2, these observations seem to be at odds with one another. What's going on here?
Spoiler Alert
In short, this ends up being exactly like the case for the "always-taken" conditional branch - we could consistently speculate if we're willing to use some other gadget to make sure that no BTB entry is present every time the branch is encountered.
I mentioned this briefly in the previous article, but earlier this year (in March) an embargo was lifted on a couple different issues that affect Zen 2 machines. The behavior in this particular case was disclosed to AMD by Grsecurity and assigned CVE-2021-26341 (see AMD SB-10263).
Like the last article, I'm not going to talk about BTB flushing at all. The Grsecurity writeup4 about this is really comprehensive, and I wanted to try to avoid repeating it where possible.
But what does this tell us about the branch predictor, if anything?
No Mispredictions?
As for "why the PMCs record no misprediction," I'm not 100% sure. It could be that PMCs are somehow failing to record a misprediction in this case, but I'd rather believe it has something to do with the fact that "discovering an unconditional direct branch" is a special kind of case.
The SOG tells us that branches are predicted "not-taken" when first discovered. However, this seems like the exact opposite of what should happen for an unconditional direct branch: it should always result in a control-flow change.
On top of that, this is a direct branch: all of the information required for resolving the branch is contained in the instruction encoding. In that sense, there's never a reason to "predict" the target of these branches, and that means there should be no reason to ever have a "misprediction."
I think the semantics here are slightly different. Instead, it seems more accurate to say that no prediction occurs.
Even though there's nothing variable about an unconditional direct branch, there's still necessarily some latency between "detecting the branch" and "resolving the branch." That seems like enough reason for the machine to continue relying on a BTB to cache the target address.
About Redirects
Despite the fact that this isn't technically a "prediction," control-flow still needs to be corrected at some point. If you stare at AMD documentation for long enough, you will eventually learn that AMD uses the term redirect to mean "a control-flow correction."
In the case where we're discovering a branch for the first time, it seems clear that we'd always expect a redirect to occur (unless maybe the branch is architecturally never-taken). Otherwise, redirects should only occur when the BTB has provided some predicted target address which doesn't match the resolved target address.
Interestingly, the Processor Programming Reference (PPR)5 for Family 17h includes a PMC event called "Branch Redirects from Decoder." If we run our test again, we can see that a redirect occurs when the branch is initially discovered:

I interpreted this to mean that "the act of decoding this branch caused a redirect," instead of "this branch was mispredicted and caused a redirect." This seems to line up with what we mentioned in the previous section about the missing events for branch mispredictions.
We can imagine a few different things that need to happen during a redirect, and they're probably somewhat expensive:
-
The correct target address has to be sent to the front-end of the machine, so that fetch and decode can resume at the correct point
-
All of the instructions from the incorrect path need to be flushed from the pipeline
-
A BTB entry needs to be created so that we can correctly predict the target address next time the branch is encountered
Presumably, the speculative window here corresponds to [part of] the latency associated with performing this kind of redirect!
About the Window Size
While we're on this train of thought, we can also try to reproduce observations
from the writeup about the size of the speculative window. I didn't go out
of the way to test other instructions, but it seems like we can insert up
to 9 NOP instructions in-between JMP and PREFETCH while still measuring
the prefetch event.
00007fe26e5a40fd: 0faee8 lfence
00007fe26e5a4100: e93b000000 jmp 0000_7FE2_6E5A_4140h
00007fe26e5a4105: 90 nop
00007fe26e5a4106: 90 nop
00007fe26e5a4107: 90 nop
00007fe26e5a4108: 90 nop
00007fe26e5a4109: 90 nop
00007fe26e5a410a: 90 nop
00007fe26e5a410b: 90 nop
00007fe26e5a410c: 90 nop
00007fe26e5a410d: 90 nop
00007fe26e5a410e: 0f0d07 prefetch [rdi]
00007fe26e5a4111: 0faee8 lfence
00007fe26e5a4114: 90 nop
00007fe26e5a4115: 90 nop
00007fe26e5a4116: 90 nop
...
00007fe26e5a4140: 0faee8 lfence
If we try to insert any more than 9 NOP instructions, the PMCs fail to capture
a speculatively-dispatched PREFETCH instruction.
Out of curiousity, I also tried longer encodings of NOP, like the full
15-byte encoding:
00007ffa5b8df0fd: 0faee8 lfence
00007ffa5b8df100: e9bb000000 jmp 0000_7FFA_5B8D_F1C0h
00007ffa5b8df105: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df114: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df123: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df132: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df141: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df150: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df15f: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df16e: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df17d: 666666666666660f1f840000000000 nop [rax+rax]
00007ffa5b8df18c: 0f0d07 prefetch [rdi]
00007ffa5b8df18f: 0faee8 lfence
00007ffa5b8df192: 90 nop
00007ffa5b8df193: 90 nop
00007ffa5b8df194: 90 nop
...
00007ffa5b8df1c0: 0faee8 lfence
Despite the fact that our test should be more costly to fetch, and despite
the fact that the decoder output each cycle is limited when handling
instructions larger than 8 bytes long, we still can tolerate 9 of these NOP
instructions.
I'm not exactly sure why this is the case though: either the redirect takes enough time to allow all of these instructions to flow through the pipeline, or it seems like our method of testing here is insulated from the additional front-end latency in this case6.
Redirect Latency?
We can also use some different PMC events to make sense of the situation. Here's some measurements using the counters for "dispatched micro-ops" and "cycles-not-in-halt."
Since our tests are wrapped up in code for reading the PMCs, we have to
have a test for the floor (meaning, with no instructions) in order to
compute a difference. I also thought it would be interesting to look
at a test with only the JMP instruction.
# Test 'floor'
| PMCx076 [LsNotHaltedCyc(0)]
| Description: Cycles not in halt
| min=79 max=79 mode=79 | dist={79: 4096}
| PMCx0ab [DeDisOpsFromDecoder(8)]
| Description: Dispatched ops from decoder (speculative)
| min=79 max=79 mode=79 | dist={79: 4096}
# Test 'jmp direct (bare)'
| PMCx076 [LsNotHaltedCyc(0)]
| Description: Cycles not in halt
| min=80 max=94 mode=80 | dist={80: 4095, 94: 1}
| PMCx0ab [DeDisOpsFromDecoder(8)]
| Description: Dispatched ops from decoder (speculative)
| min=80 max=81 mode=80 | dist={80: 4095, 81: 1}
# Test 'jmp direct'
| PMCx076 [LsNotHaltedCyc(0)]
| Description: Cycles not in halt
| min=80 max=94 mode=80 | dist={80: 4095, 94: 1}
| PMCx0ab [DeDisOpsFromDecoder(8)]
| Description: Dispatched ops from decoder (speculative)
| min=80 max=82 mode=80 | dist={80: 4095, 82: 1}
# Test 'jmp direct (9 NOPs) '
| PMCx076 [LsNotHaltedCyc(0)]
| Description: Cycles not in halt
| min=80 max=94 mode=80 | dist={80: 4095, 94: 1}
| PMCx0ab [DeDisOpsFromDecoder(8)]
| Description: Dispatched ops from decoder (speculative)
| min=80 max=90 mode=80 | dist={80: 4095, 90: 1}
Note that the dist field indicates the amount of test runs (out of 4096)
where we obtained a particular number of events. In this case, the outlier
always corresponds to the first test run: this is when we see the speculation
and redirect behavior.
Subtracting the floor measurements, we can obtain the number of dispatched micro-ops and the number of cycles-not-in-halt for each case:
| Test Case | Dispatched Micro-ops | Cycles not in Halt |
|---|---|---|
Only JMP | 2 micro-ops | 15 cycles |
Original test gadget (JMP, PREFETCH) | 3 micro-ops | 15 cycles |
Padded test gadget (plus 9 NOPs) | 11 micro-ops | 15 cycles |
It seems like in any case here, the cost of the redirect ("initially discovering an unconditional direct branch") is 15 cycles. This falls in line with some estimates for branch misprediction latency given by the SOG:
"The branch misprediction penalty is in the range from 12 to 18 cycles, depending on the type of mispredicted branch and whether or not the instructions are being fed from the op cache. The common case penalty is 16 cycles."
Although it seems we can get 10 micro-ops to be speculatively dispatched
after the JMP, it's not clear how many of these are able to be issued and
completed [out-of-order] by the time the pipeline is flushed. Our measurements
here reflect dispatched micro-ops, and not necessarily executed micro-ops.
More BTB Details
This section contains a discussion about details from AMD patents.
Click this link to unhide/hide this section.
While investigating this case with unconditional direct branches, I thought it might be useful to consult the following AMD patents:
- Multiple-table branch target buffer (US10713054B2)
- Merged branch target buffer entries (US20210373896A1)
These give some more context about the role of the BTB in the pipeline, assuming that they're actually related to the implementation that we're dealing with here. I've distilled some useful pieces of information here because the reading is a bit dry.
Branch Properties
Apart from storing predicted target addresses for branches, BTB entries also include bits that describe branch properties:
- A branch may be a
JMP, aCALL, or aRET - A branch target address may be marked as fixed or variable
- A branch has a direction, which may be
- Unconditional direct (meaning "found through a decode redirect")
- Conditional static (meaning "always-taken")
- Conditional dynamic (meaning "potentially not-taken")
And some other related points:
- All BTB entries are fixed-target by default
- Entries only become variable-target after a redirect occurs
- Entries for conditional branches are static by default
- Conditional branches only become dynamic after a redirect occurs
This isn't too suprising, especially because this perfectly matches what the SOG says. I took this to mean that the patents are at least somewhat related to the actual implementation here.
With hints about how the BTB might distinguish branch types, we can also rearticulate what the SOG says about other branch prediction structures.
The BTB applies to all branches because they all have target addresses, and because retrieving a cached target address is faster than waiting for the target address to be resolved later in the pipeline. But depending on the type of branch, the other specialized structures mentioned in the SOG may be invoked for making the prediction:
- Conditional dynamic entries defer to a Conditional Branch Predictor
- Variable-target entries defer to a Indirect Target Predictor
CALLandRETdefer to a Return Address Stack
It seems reasonable to assume that the remaining types of entries ("unconditional direct" and "conditional static") should only rely on the target address in the BTB entry for making a prediction.
Updating our Diagram
Now that we've made a few more distinctions about how the branch predictor is organized, this is probably a good time to add them to the diagram we started in the previous article.
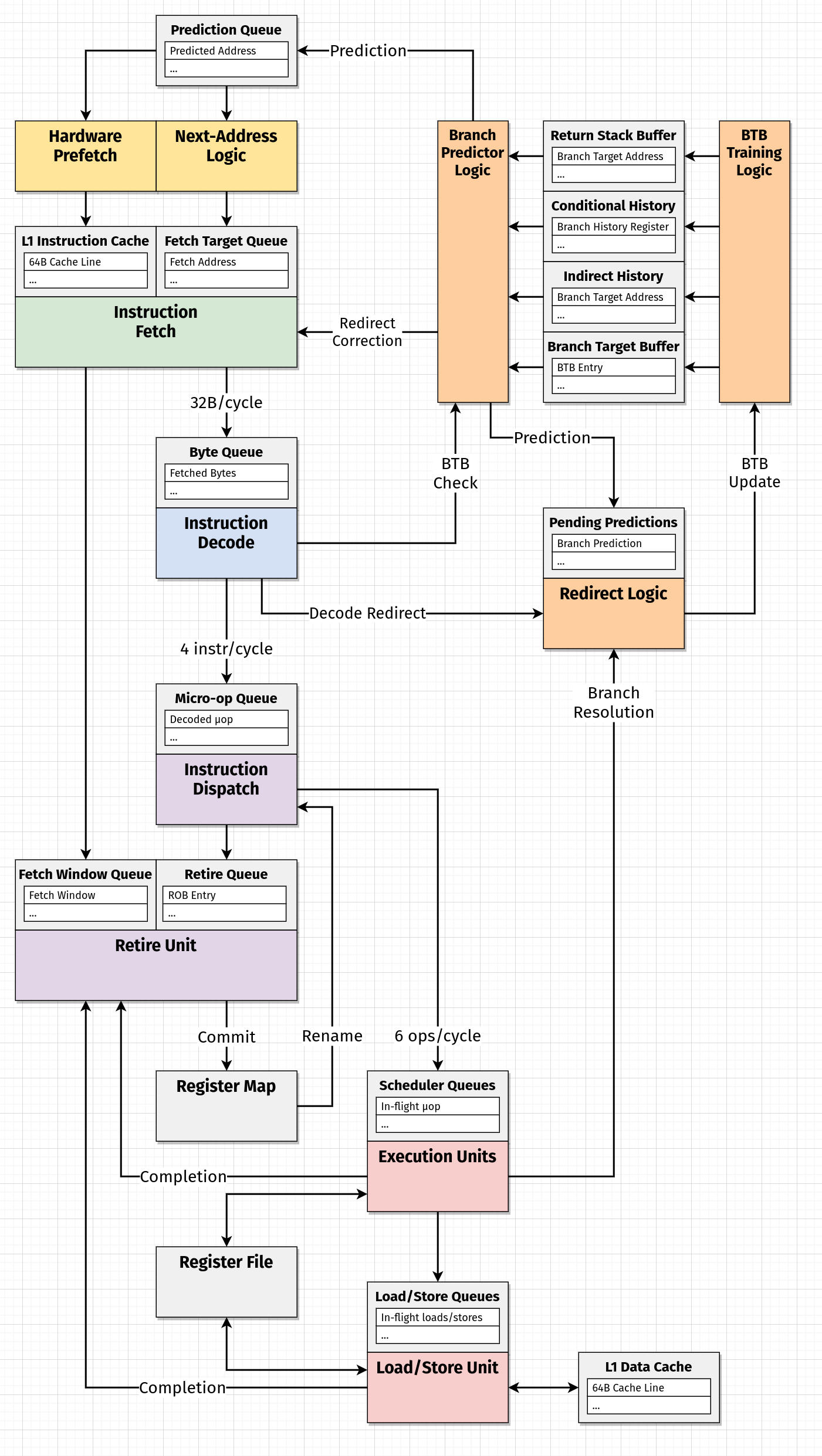
I thought this seemed reasonable, although there are obviously a lot of things that we don't have concrete answers to:
-
Where do corrected target addresses (from a redirect) enter the front-end of the pipeline? Do they go back into queues? Directly to the fetch unit? Or maybe even to the decode unit in some cases?
-
Do BTB checks and decode redirects really occur during decode? Is there any reason to believe they might happen later (i.e. at dispatch)?
-
Is there really a distinction between a "Prediction Queue" at the front of the pipeline and a set of "Pending Predictions" used to determine if a redirect occurs? I wonder if the "Fetch Window Tracking Structure" is related to this.
Redirects and BTB Updates
US10713054B2 offers some more wisdom about how redirects might be related to BTB updates too.
"The BTB training process is done through a training pipe. Each thread is associated with a mispredict register that captures information about the last redirect seen for the thread and indicates whether a BTB update is requested."
"The training pipe picks between the two threads based on requests and arbitrates through round-robin in case of request conflicts that occur when both threads request BTB training simultaneously."
"In general, training for one thread can start while the other thread is already in the training pipe. However, a thread cannot be picked if the other thread is currently being trained for the same BTB index and does not update the BTB table in time to be visible by the second training at the same index."
"BTB training happens speculatively and redirects occurring on the wrong path can cause BTB updates. However, if the mispredict register gets overwritten, training that is in progress for the thread is canceled."
Speculative redirects and BTB updates confer a lot of benefits in the best-case scenario, since the machine is potentially able to speculate far-ahead and complete a lot of work ahead of time.
But of course, this paragraph is scary when we put on the security hat: it says that the BTB is a shared resource between threads, and that BTB updates can be speculative too. That kind of situation is related to the principles underlying the original Spectre (Variant 2) mechanism, which is also called [appropriately] "Branch Target Injection."
I didn't realize this before, but even before testing the unconditional direct branch with the "decode redirect" PMC event, I mentioned it in the first article while trying to list all of the "speculative events" defined in the PPR:
PMCx091 [Decoder Overrides Existing Branch Prediction (speculative)]
(Core::X86::Pmc::Core::BpDeReDirect)
Breakpoint
This series just keeps getting longer and longer, and it's easier for me to handle in discrete jumps (ha). I think at this point, we're probably going to be doing one for each type of branch.
Thanks for reading!
Resources and Footnotes
In my previous article, I explained that we emit an LFENCE
instruction before the start of the test. This was to supposed to ensure that
no speculative paths into the test are evaluated, meaning that we should only
observe speculative events caused by behavior within the body of our test.
If we believe that LFENCE works as-perscribed, this seems like a reasonable
assumption.
I initially thought that this might have something to do
with the initial LFENCE guarding the start of our test, but I'm not too
sure about it. My thought was: LFENCE serializes dispatch, but it's
possible that while the back-end is draining, fetch and decode are still
allowed to buffer up macro-ops in the op queue. Or maybe the micro-op cache
is involved here? I don't have a concrete answer.